
This term I’m auditing CSC311 Introduction to Machine Learning. I’ve tried learning this topic before, but it wasn’t at the right level for me. This time I’m optimistic because my colleague Sonya Allin is teaching the course, and I feel comfortable bombarding her with naive questions.
As I was sitting in the first class, I had my mathematician hat on and I noticed some things. I’m not saying these are deep, or unknown things, but they were interesting to me. Maybe they’ll be interesting to you too!
Observation 1: When we turn a picture into a vector we seem to lose a lot of geometric data
A standard way of storing a (greyscale) picture as data is to first write it as a matrix of data (an nxn table) where the entries are intensities (on a scale of 0-255). Then it cuts chopped up and reconstituted into a vector.
This usually looks something like:
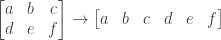
When I saw this, I was quite surprised. This is definitely a way to translate something into a vector, however:
- It loses some geometric data. (i.e. A picture of the number 0 gets cut up so that it no longer is connected.)
- What happens if we cut it up in different ways?
But, even more surprisingly, many machine learning algorithms don’t care about this, and can recover the geometric relationships (!) because of…
Observation 2: Euclidean distance weights all dimensions equally, so any ML algorithm based on it (like least-squares, or k-nearest-neighbor) gives the same classification, regardless of the method of “vectorizing” the picture
Think about finding the distance between two points in 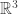
So when an algorithm like least-squares or k-nearest neighbor only uses Euclidean distance to decide how to classify a new point, even if two different people vectorized the picture in different ways, the classification will be the same. This is because the two people will simply have vectors that are permutations of each other.
This is quite surprising to me, and seems to say “the relative geometric info of the pictures is preserved, even if individual pictures are being distorted”.
A simple example of this would be the top left pixel of any handwritten letter pictures from the MNIST database. All these pixels will be 0 intensity. So even if you permute where that component is, all pictures will still have a 0 in the same place as each other.
Lesson: Translating/Distorting all your data in the same way preserves relationships between the data, even if it distorts the original data from its translation
